그리고 다시 carbamyl 은 carbo + -amide의 carbamide(Urea, 요소)에서 질소 하나가 제거된 잔기의 형태이므로 -yl을 붙였다.
Dibenzoazepine <출처: wikipedia>
또한 모핵을 이루는 3환의 dibenzoazepine 중에서 뒤의 azepine을 가지고 와서 carbam-의 뒤에 붙였다.
dibenzoazepine은 다시 di+benzo+az-+(h)ep(ta-)+-ine으로 분류되는데, di는 두개, benzo는 벤젠기가 직접 붙어있는 형태를 말하고, az-는 azo기도 있지만, 사실 질소가 들어간 물질에 다 쓸 수 있는 말이므로 거기에서 az를 가져왔고, 7을 뜻하는 hepta-에서 ep를 가져왔고, 질소가 붙은 물질의 어미로 자주 쓰이는 -ine을 조립하여 만든 말이다.
그리고 사실 화학구조에서 7개의 탄소로 이루어진 기본 구조를 heptane이라고 하는데, 이것은 프랑스 말로 '7개로 구성된'이라는 뜻에서 가져왔다고 한다. 그러나 영어에서도 많이 쓰인다.
2. [VMWare 다운받기&설치]윈도우 버전을 클릭하여 다운 받은 뒤, 실행 후 next를 눌러서 설치를 완료합니다.
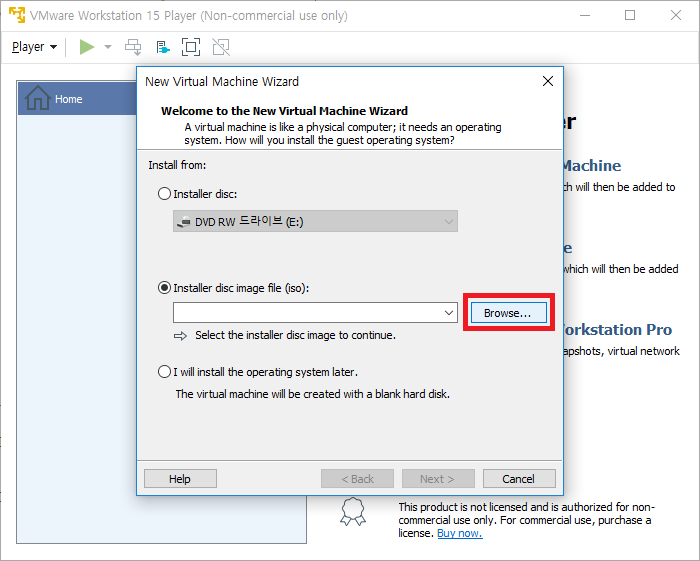
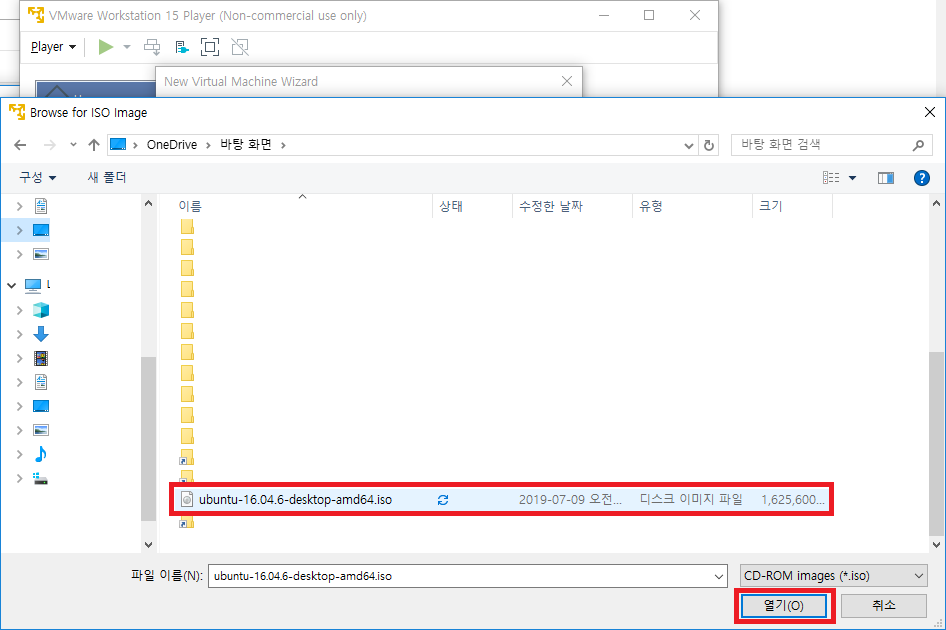
3. [Ubuntu 다운받기] VMware가 설치되는 동안 Ubuntu 홈페이지에서 16.04 LTS 버전 64-bit Ubuntu ISO 파일을 다운받습니다. (64-bit PC (AMD64) desktop image 링크 클릭) [다운받게 되면 뭔가 zip프로그램에서 열 것 처럼 나와있는데, 얘는 압축풀면 안됩니다! 나중에 나올 iso disc image 올릴 때 iso 그대로 사용하는 겁니다.] http://releases.ubuntu.com/16.04/
1) [git init] 처음에 깃한테 어떤 폴더를 보라고 시킵니다. '야 여기 좀 보고 앞으로 이 폴더에서 일어나는거 싹다 기록해놔.' 서기를 정하고 서기한테 '이제 우리가 너한테 모든 파일을 다 보낼거야'라고 합니다.
2) 열심히 그 폴더 안에서 지지고 볶습니다. 새 폴더도 만들고 코딩한 파일도 만들고 하면서요. 서기한테 보내기 전 내 컴퓨터에서 열심히 작업을 하는 것과 같습니다.
3) [git status] 그리고 깃한테 한번 쓱 물어봅니다. '잘 기록했니?' (물론 굳이 안물어봐도 됩니다. 알아서 잘 하니까요? 그치만... 궁금하잖아요?) 그러면 컴퓨터인 깃은 싹다 기록을 해놨다고 얘기를 하죠. 서기도 마찬가지 일 겁니다.
4) [git add] 그렇다면 그 변경사항 중 변경이 저장되길 원하는 것만 선택합니다. 이 순간부터 단순히 컴퓨터에 저장된 것이 아닌 내부적으로 '스테이지'라고 불리는 곳에 따로 입력해둡니다. 서기의 컴퓨터에게 보내기위해 메일에 따로 업로드를 합니다.
5) [git commit [파일명] -m "뭐라뭐라"] 그리고 현재 서기한테 던져준 파일들을 한 뭉텅이로 만들고 이 뭉텡이가 뭔지 설명을 적어줍니다. 서기 컴퓨터에 저장할 내용입니다. 여기까지 하면 서기가 서기 컴퓨터에 파일을 영구히 저장했습니다. 이것을 '레포'라고 부릅니다.
6) 깃헙이라는 클라우드 서비스에 프로젝트 저장소를 만듭니다. 가령 서기가 단톡방 혹은 옵톡을 파는 것과 같습니다.
7) [git remote add] 컴퓨터에게 깃헙 주소를 알려줍니다. 사람들에게 옵톡 주소를 알려주는 것과 같습니다. 딱 한번만 알려주면, 다른 사람들이 방에 주소 없이 들어올 수 있듯 깃헙에도 한번만 해주면 따로 이 과정없이 바로 올릴 수 있습니다.
8) [git push] 그리고 마지막으로 깃헙에 올리면 끝납니다. 서기도 단톡방에 파일을 올려서 모든 팀원들이 볼 수 있게 하였습니다.
2. 저번에 git clone했던 models폴더 내의 research 안에서 data라는 폴더를 새로 만들어줍시다.
3. 다운로드 받은 images.tar.gz과 annotations.tar.gz파일을 압축을 풀어주고, 각각 생성된 images폴더와 annotations폴더를 그대로 data라는 폴더 안에 넣어 줍시다.
4. 구글 측에서는 항상 데이터의 인풋을 tfrecord의 형태로 입력하기를 권장합니다. 구글에서 배포한 이 예시에서도 tfrecord를 사용하게 되는데요. 물론 튜토리얼 과정이기 때문에 구글측에서 이미 Oxford-IIIT Pets Dataset을 TFrecord로 만드는 파일 역시 object-dection폴더 안에 들어있습니다. 참고로 [username]은 각 컴퓨터에 맞는 사용자 이름으로 바꾸어 주셔야 합니다!
구글 문서에서 tfrecord를 만들 때 WARNING이라고 몇개 뜨는 게 있는데, 별로 신경쓰지 않아도 된다고 나와있습니다.
5. 저대로 실행시키면 우리가 만든 data폴더에 train.pet_faces_train.record-00000-of-00010로 시작하는 파일이 10개 생성되고, pet_faces_val.record-00000-of-00010로 시작하는 파일이 10개 생성됩니다.
6. 인풋데이터는 이제 완성되었습니다. 이제 학습을 시키면 되는데, 완전히 처음부터 학습시키기에는 우리가 기본적으로 가지고 있는 컴퓨터의 컴퓨팅 파워가 너무너무너무 작습니다. 그러니 누군가가 먼저 엄청난 컴퓨팅 파워로 학습시켜놓은 것을 가져다가 마지막에 끝단만 살짝 바꾸어서 사용해보도록 하겠습니다. 이것을 transfer learning 혹은 fine tunning이라고 합니다. 먼저 이미지넷에서 상받은 Resnet으로 MS-COCO데이터셋에 대해서 Faster-RCNN 기술로 학습시켜놓은 훈련된(pretrained) 데이터를 받아오겠습니다. >>링크<<
불러오는 중입니다...
7. 다운받은 faster_rcnn_resnet101_coco_11_06_2017.tar.gz를 압축을 풀면 model.ckpt로 시작하는 파일이 3종류가 있습니다.(~.data-00000-of-00001, ~.index, ~.meta) 전부 복사한 뒤 우리의 data폴더 내에서 다시 model이라는 폴더를 만들어 준 뒤에 거기에 붙여넣어 줍니다.
8. 이제 pipeline이라는 config파일만 만들어주면 바로 tfrecord의 데이터를 pretrain된 모델을 가지고 새로 학습을 시작합니다.
8-1) 먼저 jupyter와 같이 문서를 수정할 수 있는 에디터를 켜주세요. 메모장도 괜찮습니다.
8-2) object_detection폴더 안의 samples폴더 안의 configs 폴더로 들어갑니다.
8-3) .config라 쓰여있는 파일이 많은데, 여기에서 faster_rcnn_resnet101_pets.config 파일을 열어주세요.
8-4) fine_tune_checkpoint를 검색하셔서 그 오른쪽에 다운받은 model.ckpt위치를 적어줍니다. 저희가 진행한 상에서는 아래와 같이 적어주시면 됩니다.
8-7) eval_input_reader에는 train_input_reader에서 적어주었던 주소값을 그대로 다시 써주면 됩니다. 다만 input_path에서 pet_faces_train.record-?????-of-00010을 pet_faces_val.record-?????-of-00010으로만 바꿔주시면 됩니다.
(사실 PATH_TO_BE_CONFIGURED 부분만 바꿔주면 되지만, 헛갈림 방지를 위해 전부 작성하였습니다.)
9. 자 이제 학습을 시작합시다. 학습은 object_detection폴더 안에 있는 moel_main.py가 합니다. 그리고 결과 ckpt가 저장될 위치는 data폴더 안에 output폴더로 지정하겠습니다. 먼저 data폴더 안에 output폴더를 만들어주세요. 아래 구문을 실행하면 자동으로 학습이 시작됩니다. Warning 같은 글자가 계속 뜨지만 신경 안쓰셔도 됩니다.
10. 만약 OOM에러(OOM when allocating tensor with shape[1,1024,38,57] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc)가 나신다면 그래픽카드 메모리 부족이 원인이므로 .config파일에서 제일 상단에 보이는 keep_aspect_ratio_resizer에서 크기를 줄이고 진행하시면 진행이 됩니다. 혹은 컴퓨터를 재부팅하여 리소스를 다시 확보하는 것도 괜찮은 방법입니다.
맨 앞의 O는 출처가 불분명하다. 그러나 thienobenzodiazepine에 달린 잔기가 1-methylpiperazine이므로 맨 앞의 one의 O일 것이라는게 높은 확률로 추측이 된다.
lan은 피페라진 구조에서 ran을 가져오지만, 맨 앞의 O와 붙어 r을 l로 바꾸어서 사용한 것으로 추정되며, 구조중에서 가장 메인이 되는 3환계 구조의 이름은 thienobenzodiazepine에서 azepine을 가져온 것으로 보인다. 여기서 다시 azepine을 zapine으로 애너그램 및 모음 변경. 뒤에 azepine -> zapine 변경은 비정형 항정신병제인 클로자핀(clozapine) 등에서도 보인다.
<출처: 위키피디아>
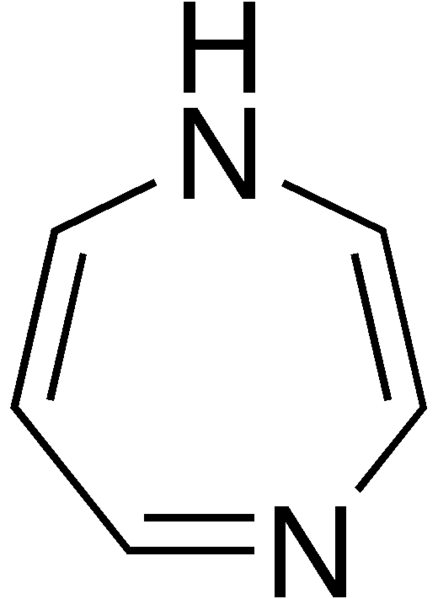
Diazepine은 di-az(o)-(h)ep(ta)-ine으로, 위 이미지에서 보이듯, '두개의 azo가 붙은 7각의 질소가 들어간 구조'란 뜻이다. 위의 구조는 1,4 diazepine 구조이며, 1,3 혹은 1,2 위치에도 질소가 배열될 수 있다.
azo기는 질소질소 이중결합에 쓰이는 말이지만, 탄소가 끼어들어가며 공명구조를 이루었을 때 그 구조를 diazo-라고 부르는 듯 하다.
참고로 -ine의 사전적 뜻은 'forming names of alkaloids, halogens, amines, amino acids, and other substances.' 즉, 알칼로이드나 할로겐, 아민, 아미노산 과 같은 물질에 붙는 접미사이다. 보통 질소를 기반으로 한 구조에 잘 붙는다.
이 기본 모핵에 benzo기와 thieno기가 붙어 커다란 thienobenzodiazepine기를 만들고 여기에 1-methylpiperazine이 붙어 만들어지는 구조이다.
리스페리돈이 속한 2세대 혹은 비전형이라고 불리는 항정신병 약물은 세로토닌-도파민 길항제(antagonist)이다. 1세대 도파민 수용체 길항제(DRAs)보다 D2 수용체에 대한 세로토닌(5-HT2) 수용체 차단 비율이 높다. (세로토닌 더 많이 길항) 비전형 항정신병 약물은 다른 수용체와 결합하여 나타나는 추체외로 증후군이 더 적게 나타나므로 자주 처방되는 편 그러나 리스페리돈은 다른 2세대 항정신병 약물보다 추체외로 증상이 잘 나타나는 편이다.