피타고라스와 작두콩(잠두): 제 1계명 "콩을 먹지 말라"
오늘은 아주 흥미로운 사실에 대해 알아보려고 합니다.
여러분들은 피타고라스를 알고 계신가요?

피타고라스는 기원전 570년 경 태어난 사람으로 알려져 있는데요, 우리에게는 삼각형의 빗변의 제곱은 밑변의 제곱과 높이의 제곱의 합과 같다는 '피타고라스 정리'라는 것으로 제일 유명하죠.

그러나 이런 피타고라스가 한 종교의 교주였다는 사실을 알고 계셨나요?
피타고라스는 피타고라스 학파를 만들며 여러 계명들을 만들었는데요, 그 중에 제일 재밌는 계명이 제 1계명입니다.
바로 "콩을 먹지 말라"는 건데요, 대체 왜 이 계명이 생겼을까요?
썰은 정말 다양합니다.
피타고라스가 채식주의자임에도 콩을 금지한 이유는 소화가 잘 안되어서 라거나, 이상한 종교적 믿음으로 콩과 사람이 비슷해서 등등 얼핏 듣기에는 잘 이해가 가지 않는 썰들이 있습니다. 특히나 채식주의자에게 콩은 단백질 보급의 주요 원천이기에 그 옛날에 채식주의자가 콩을 금지했다는건 경험적으로도 뭔가 안맞는 이야기이기도 하구요.
그러나 여기에는 나름 아주 매력적인 썰이 있습니다.
바로 피타고라스가 콩을 먹으면 아팠었기 때문이라는 썰입니다. 결국 무슨 질환을 가지고 있었다는 것이었겠죠?
도대체 이게 왜 매력적인 썰일까요?
각 파트별로 나눠서 살펴보죠.
콩, 질환, 고찰 그리고 결론 입니다.
1. 콩

그 시절 지중해에서 나는 콩들은 '작두콩' 혹은 '잠두'(혹은 누에콩, 파바빈, fava bean, broad bean)라고 불리는 콩들이었습니다.
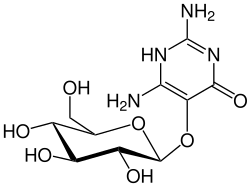
이 작두콩에는 Vicin(비신)이라는 성분이 있는데, 이 비신이라는 성분은 자체로는 아무런 해가 없습니다만, 이게 대장에서 정상세균총(micro flora)에 의해 가수분해되면, aglycon(아글리콘: 글루코오스(6탄당) 형태가 빠진)인 divicin(디비신)이라는 성분으로 대사되고, 이 성분은 활성산소(free radical) 생성 물질이 됩니다. 그리고 이 산화 능력은 체내 자체적인 환원 물질인 glutathione(글루타치온)에 작용, 이를 소모하게 합니다.
정상인에게는 비록 이 물질이 생성된다하더라도 빠르게 글루타치온을 재생성 할 수 있기 때문에 문제가 되지 않지만, 몇몇 사람에게는 이게 큰 문제를 일으킬 수 있습니다.
그 중 가장 유명한 것이 G6PD 결핍증입니다.
2. 질환
G6PD 결핍증(glucose-6-phosphate dehydrogenase deficiency, 6-인산포도당탈수소효소 결핍증)은 오탄당 인산경로(pentose phosphate pathway)에 쓰이는 G6PD가 결핍되어 생기는 질환입니다.
특히나 적혈구의 대사에서 중요한 효소지요.
산화적 손상을 일으키는 자유라디칼을 제거하는 '글루타치온(Glutathione)'을 환원시키는데 NADPH가 사용되는데, 적혈구에서는 이 오탄당 인산경로가 유일한 NADPH 공급원입니다.
따라서 여기서 이 환원적 환경을 만들어 낼 수 있는 G6PD가 결핍되게되면 결과적으로 적혈구는 매우 불안정한 상태가 됩니다. 약간의 자극에서 적혈구 세포막이 터질 수 있고, 결국 이는 용혈성 빈혈로 나타나게 되죠. 특히나 적혈구가 산화적 상태로 불안정하다는 것을 주목해야 합니다. 결국 외부에서 산화적 스트레스가 오면 아주 쉽게 적혈구가 용혈 될 수 있다는 것이죠.

다시 생각해보면, 결론적으로 피타고라스는 이 질병을 가지고 있었을 것이며, 그렇기에 대사과정에서 활성산소를 만들어내는 작두콩을 먹으면 용혈성 빈혈로 매우 아팠을 것입니다.(이를 잠두중독증(favism(파비즘))이라 하며, 잠두(누에콩)의 이름인 fava bean에서 유래했습니다.)
그럼 피타고라스는 왜 이 질병을 가지고 있었을까요?
3. 고찰

이 G6PD 결핍증은 X염색체 연관으로 유전됩니다. 즉, 여자는 보인자, 남자는 무조건 증상이 발현된다는 말이지요.
보통 한 지역에서 유전병이 계속 지속되는 이유는, 그 유전병을 가짐으로 인해서 얻는 이득이 있을 때 사라지지 않고 유전병이 유지되는 경향이 있습니다. 겸상 적혈구 빈혈증도 말라리아에 대해서 저항성이 있기 때문에 정상적인 적혈구를 가진 사람보다 생존에 유리해서 계속해서 그 유전병이 남아있죠.
똑같이 G6PD결핍증도 적혈구를 약하게 만들기 때문에 말라리아에 저항성이 생깁니다. 정확히는 말라리아가 원충으로 적혈구에 들어갔을 때 거기서 성숙을 못하게 적혈구를 쉽게 파괴시켜버리기 때문에 말라리아에 대해 저항성이 생기는거죠.
특히나 과거 지중해에서 말라리아가 호발했기 때문에(이는 지중해성 빈혈 등 빈혈 관련 유전병이 지중해에서 유래한 것이 많다는 것이 반증하기도 합니다.) 오히려 정상인보다 G6PD 결핍증을 가진 사람이 생존에 더 유리했을 것입니다.
4. 결론
결국 이 모든 내용을 조합해보자면, 말라리아가 호발하던 지중해에서 태어난 피타고라스는 G6PD 결핍증을 가지고 있었고 작두콩을 먹고 잠두중독증(favism)으로 매우 아팠었을 겁니다. 그래서 교주가 된 이후에 제 1계명을 "콩을 먹지 말라"고 했겠죠.
그리고 또하나 재밌는 사실은 피타고라스의 죽음도 콩과 연관되어 있다는 점입니다.
피타고라스의 죽음도 썰이 정말 많지만, 재밌는 점은 모두다 콩과 관련되어있습니다.
도망가던 중에 콩 밭을 지나다가 그자리에서 쓰러져 죽었다던가, 결국 콩 밭을 지나지 못하고 잡혀서 죽었다던가 하는 이야기지요
오늘 주제 어떻게 흥미로우셨나요?
다음에 더 재밌는 주제로 찾아오겠습니다!